"Grokking Simplicity: Taming Complex Software with Functional Thinking" by Eric Normand is a book that introduces the principles of functional programming in a practical and approachable way. It focuses on simplifying complex software development tasks by applying functional programming concepts.
The book teaches how to write simpler, cleaner, and more reliable code by avoiding shared state, mutable data, and side-effects. It's particularly useful for developers who are accustomed to object-oriented programming and want to explore functional paradigms.

The "Grokking" series, in general, aims to make complex technical topics accessible and understandable. The books in this series are known for their clear, concise explanations and practical examples. They are designed to help developers 'grok', or deeply understand, technical concepts that might otherwise seem intimidating or complex.
Book Introduction
Talks about major definitions:
- Functional programming a programming style that uses only pure functions.
- Side effects are any behavior of a function besides the return value.
- Pure functions depend only on their arguments and don't have any side effects.
Part 1: Actions, Calculations, and Data
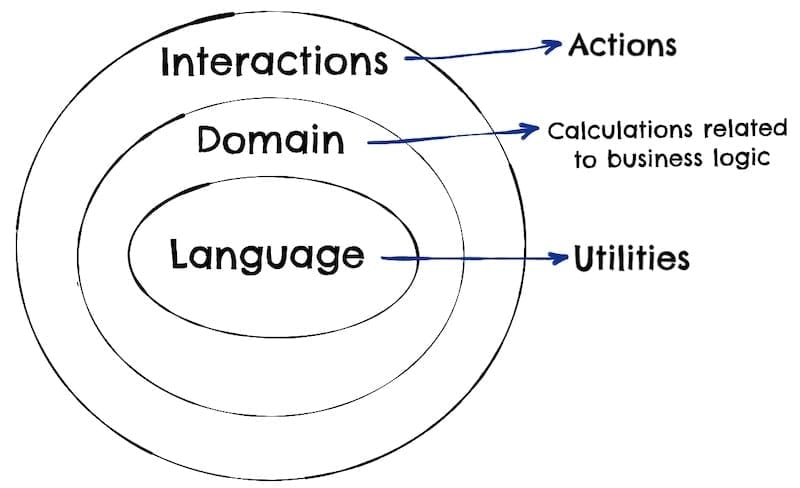
In this section, Normand introduces a fundamental distinction between different types of operations in programming: actions, calculations, and data.
Actions (side effects)

Actions are operations that have side effects or depend on external systems. They might involve things like updating a database, sending a network request, or altering the state of the application.
The explicit inputs are the arguments.
The explicit output is the return value.
Any other way information enters or leaves the function is implicit.
An Action is anything that depends on when it is run, or how many times it is run, or both.
If you call an action in a function, that function becomes an action.
Calculations (pure functions)

Calculations are operations that are deterministic and side-effect-free. Given the same inputs, they always produce the same outputs. Calculations are easier to test, reason about, and parallelize.
Referentially transparent is when you can replace a call to a function by its result.
Data (facts about events)

Data refers to the information that the program manipulates. In functional programming, data is often treated as immutable, meaning it can't be changed once created. This immutability can lead to more predictable and less error-prone code.
Other Topics from Part 1
Copy-on-write
Copy-on-write is a strategy used to efficiently manage data that is meant to be immutable, which is a key principle in functional programming. It involves creating copies of data structures only when modifications are needed, thus preserving the original data. This approach aligns with the immutability principle in functional programming, reducing memory and processing overhead by avoiding unnecessary data duplication. Copy-on-write also aids in maintaining a history of data states, which can be useful for debugging and tracking changes over time.
Defensive copying
Defensive copying in programming is the practice of creating a new instance of an object before passing it around, to prevent accidental modification of the original object. It can involve shallow copying, where only the object itself is duplicated, or deep copying, where the object and all objects it references are fully duplicated. This technique is crucial in maintaining the immutability of data, ensuring that functions or methods do not unintentionally alter shared or global state, thus preserving the integrity and predictability of the program’s state.
Stratified Design
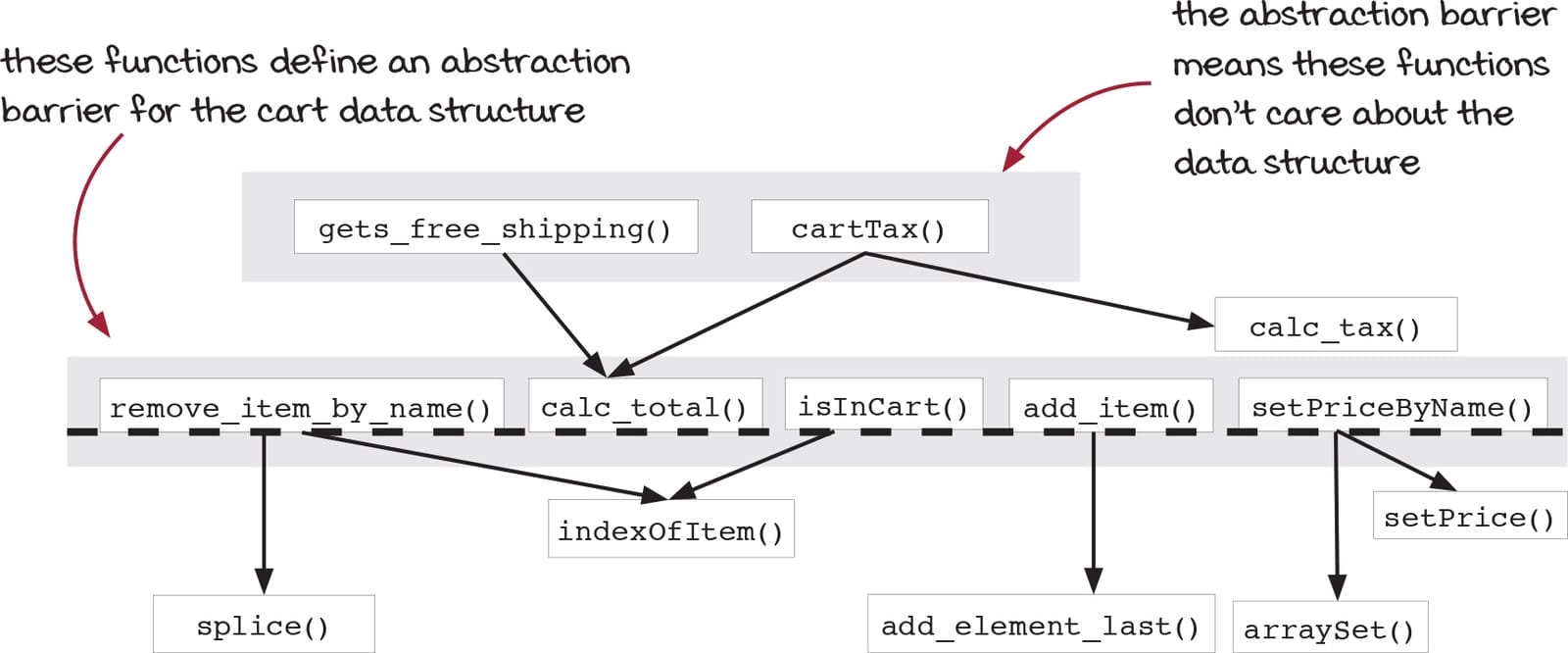
It's a design approach that involves organizing code into different layers, where each layer abstracts the complexity of the layer below it. This approach is particularly relevant in functional programming, but can be applied in any programming paradigm.
- Business rules
- Domain rules
- Tech stack
By keeping our interfaces minimal, we avoid bloating our lower layers with unncessary features.
Code graphs
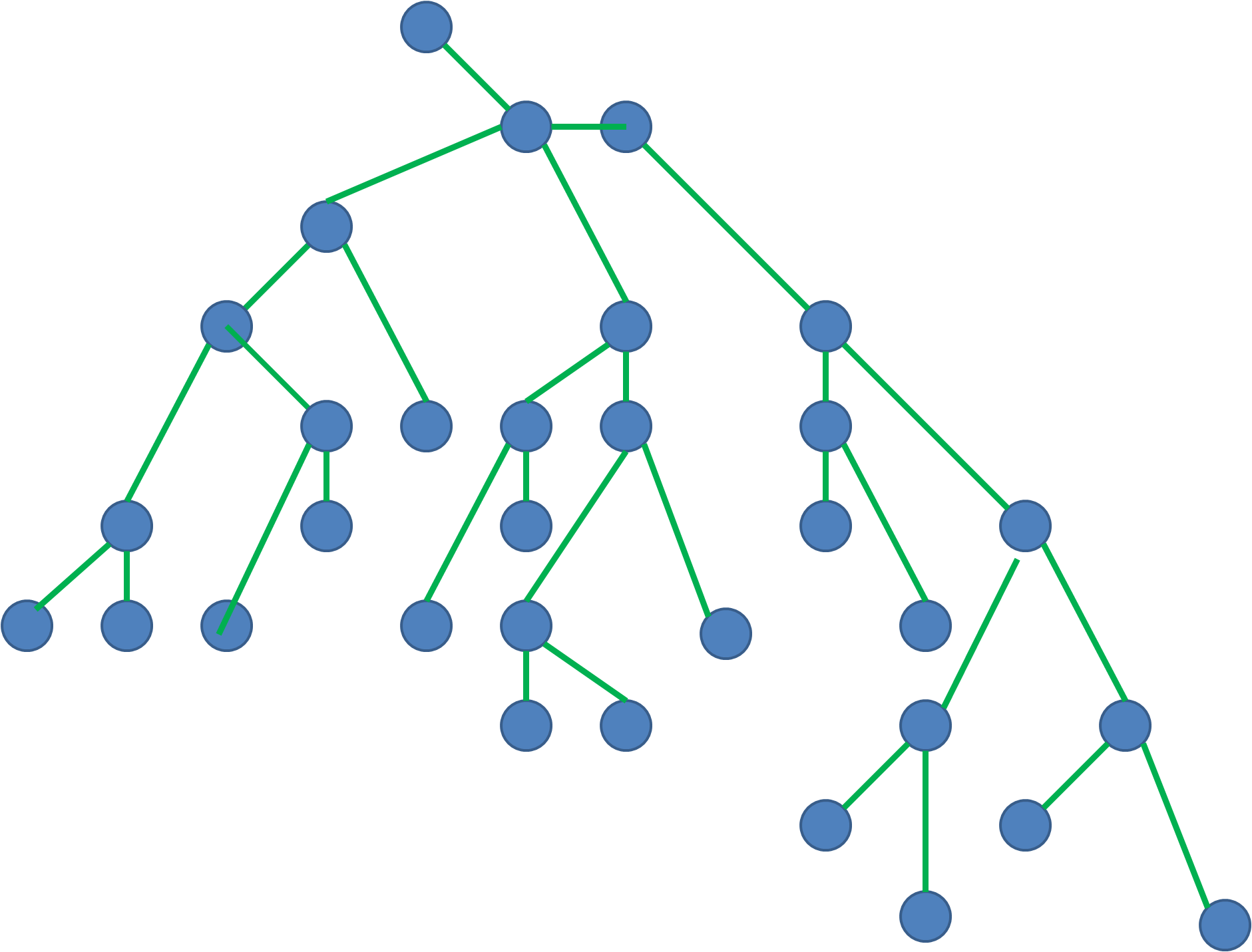
Code graphs are used as a visual tool to understand the flow and dependencies within a codebase. They represent the relationships and interactions between different parts of the code, such as functions, modules, and data structures. By mapping out these elements and their connections, code graphs help in identifying dependencies, understanding how data flows through the system, and pinpointing areas of complexity. This visualization aids in better comprehension and refactoring of the code, aligning with the book's focus on managing complexity in software through functional thinking.
Part 2: First-Class Abstractions
The second part of the book delves into the concept of treating functions as first-class citizens in programming. This means functions can be assigned to variables, passed as arguments to other functions, and returned from functions.
Higher-Order Functions (HOFs)

These are functions that operate on other functions, either by taking them as arguments or by returning them. They are a powerful abstraction tool in functional programming.
Here's why they are considered beneficial:
-
Abstraction and Reusability: HOFs allow you to abstract common patterns of computation, leading to more reusable code. For example, functions like map, filter, and reduce are high-order functions that abstract the pattern of iterating over a collection, allowing for a more declarative and reusable approach to processing data.
-
Modularity and Maintainability: By encapsulating behaviors in smaller, composable functions, HOFs promote modularity. This makes your codebase more maintainable, as it's easier to understand, test, and debug small, focused functions.
-
Flexibility and Customization: HOFs can be used to create more specific functions from more general ones. This ability to customize functionality without rewriting code from scratch adds flexibility to your codebase.
-
Reduced Boilerplate: They can help in reducing repetitive code (boilerplate). By applying the same high-order function in different contexts, you can achieve different behaviors with minimal code changes.
-
Functional Composition: HOFs are key to functional composition, where you build complex operations out of simpler functions. This can lead to more readable and expressive code.
-
Easier Asynchronous Programming: In JavaScript, HOFs are particularly useful for asynchronous programming patterns. Functions like Promise.then are high-order functions that help manage asynchronous operations more effectively.
-
Improved Code Expressiveness: They can make code more expressive and easier to understand. Instead of writing complex loops and conditionals, you can use HOFs to describe what you want to achieve in a more declarative way.
Composition and Piping
Techniques for building complex operations out of simpler functions. By composing smaller functions, developers can create more complex functionality in a readable and maintainable way.
const double = x => x * 2;
const increment = x => x + 1;
// Composition (right-to-left)
const doubleThenIncrement = x => increment(double(x));
console.log(doubleThenIncrement(3)); // Output: 7 (double 3 to get 6, then increment to get 7)
const double = x => x * 2;
const increment = x => x + 1;
// Piping
const pipe = (...fns) => x => fns.reduce((v, f) => f(v), x);
const incrementThenDouble = pipe(increment, double);
console.log(incrementThenDouble(3)); // Output: 8 (increment 3 to get 4, then double to get 8)
Functional Techniques in Practice
Applying functional programming principles in real-world scenarios, showing how they can simplify complex problems and lead to more maintainable code.
Recursion
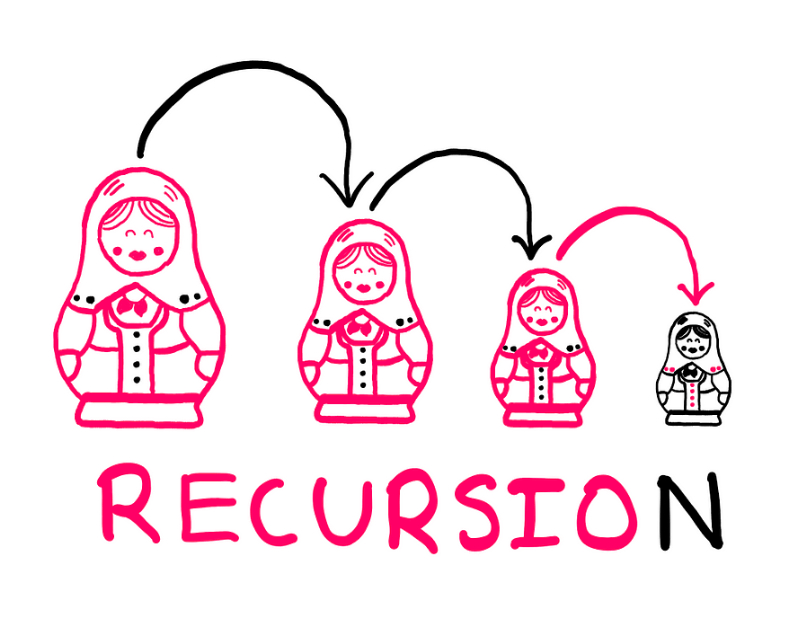
Recursion is a technique where a function calls itself to solve a problem. In the context of this book, recursion is presented as a powerful tool for processing data structures, particularly when iterative approaches (like loops) are less suitable or harder to read.
Timelines
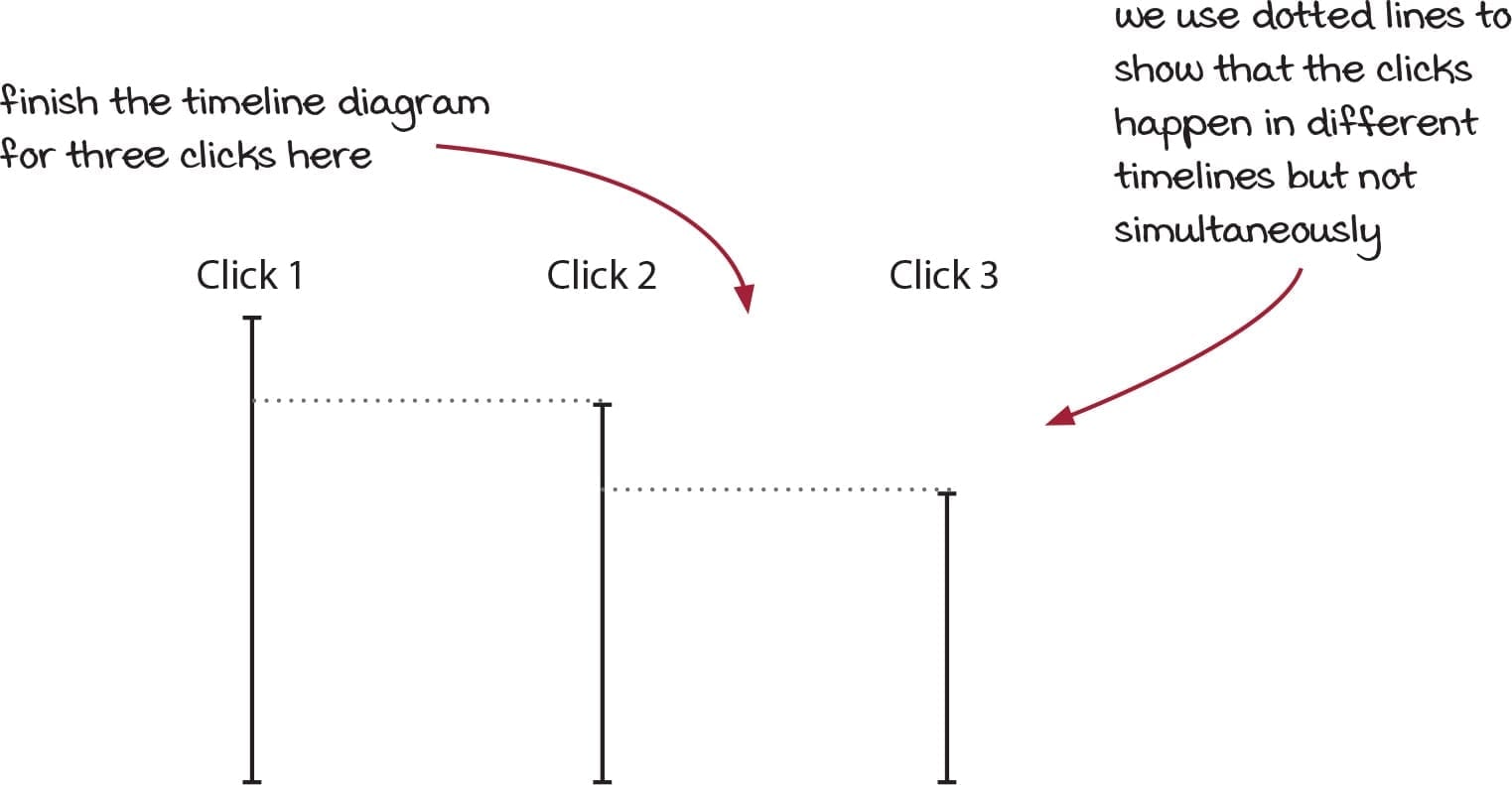
Timelines are used as a conceptual tool to understand and manage state changes over time in software development, especially in the context of functional programming. The key aspects of timelines in the book are:
- Visualizing State Over Time: Timelines help in visualizing how the state of a system or a variable changes over time. This visualization aids in understanding the flow of data and the evolution of state throughout the program.
- Dealing with Immutability: Functional programming emphasizes immutability, where data structures are not altered once created. Timelines support this concept by representing state changes as distinct and immutable states at different points in time, rather than as mutations to a single state.
- Understanding Side Effects: In functional programming, managing side effects (like I/O operations, database calls, etc.) is crucial. Timelines provide a way to conceptualize when and how these side effects occur relative to the state changes in the application.
- Simplifying Complex Logic: By mapping state changes on a timeline, complex logic, particularly involving asynchronous operations or state transitions, becomes easier to reason about.
- Event Sourcing and Debugging: Timelines align with the event sourcing pattern, where changes are stored as a series of events or states over time. This approach is beneficial for debugging, allowing developers to trace back through the timeline to understand the state changes leading to a particular event.
Concurrency primitive
A concurrency primitive is a basic building block used to manage concurrent operations in programming. These primitives are essential tools for handling multiple processes or threads that operate independently but may need to coordinate or synchronize at certain points.
Concurrency primitives help in:
- Managing shared resources.
- Synchronizing the execution of concurrent tasks.
- Handling communication between concurrent tasks.
Queues for async calls

The idea is to use a queue to control the execution order of asynchronous tasks, ensuring they are processed one after another, rather than concurrently. This approach is particularly important in scenarios where the order of operations matters, or when one operation's output is the input for the next.
Cut function

It is a higher-level function designed to manage and coordinate asynchronous operations, particularly useful in segmenting tasks and handling them in an organized manner.
The function is used to segment a series of tasks or operations into discrete chunks that can be processed in parallel, and then to synchronize or merge these parallel streams of execution at specific points. Here's a breakdown of its purpose:
Reactive Architecture
"Its main organizing principle is that you specify what happens in response to events."
The Reactive Manifesto (reactivemanifesto.org)
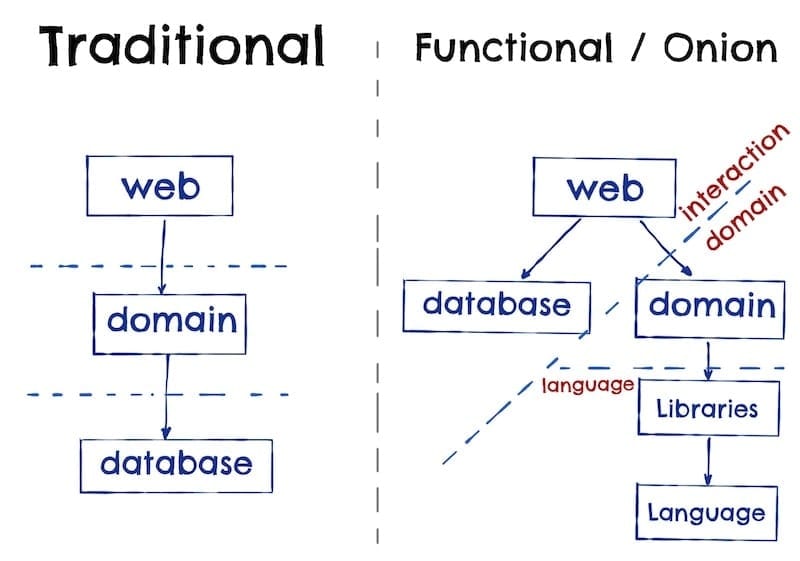
Onion Architecture
The Onion Architecture advocates for dependencies to point inwards. Higher-level layers can depend on lower-level layers, but not vice versa. This structure facilitates a more robust design, as changes in external systems like databases or UI frameworks have minimal impact on the core domain logic.
The book uses the database as an example to illustrate how in traditional architectures the database often dictates the design. In contrast, the Onion Architecture decouples the domain logic from the database, promoting a domain-centric design.